We recently helped Yoshua Bengio write up his mathematical argument for Scientist AI. Our role was to be an internal red-team but we ended up doing about 1000 hours of developing the argument and editing the text.
The dominant current training process (just optimise outcomes bro) blatantly applies selection pressure toward strategic outputs (lying, sycophancy, cheating, etc). If this pressure continues to increase (with RL) we might be in trouble. In this paper “implicit agency” a slightly sharper replacement for the classical idea of “instrumental convergence towards harmful goals”.
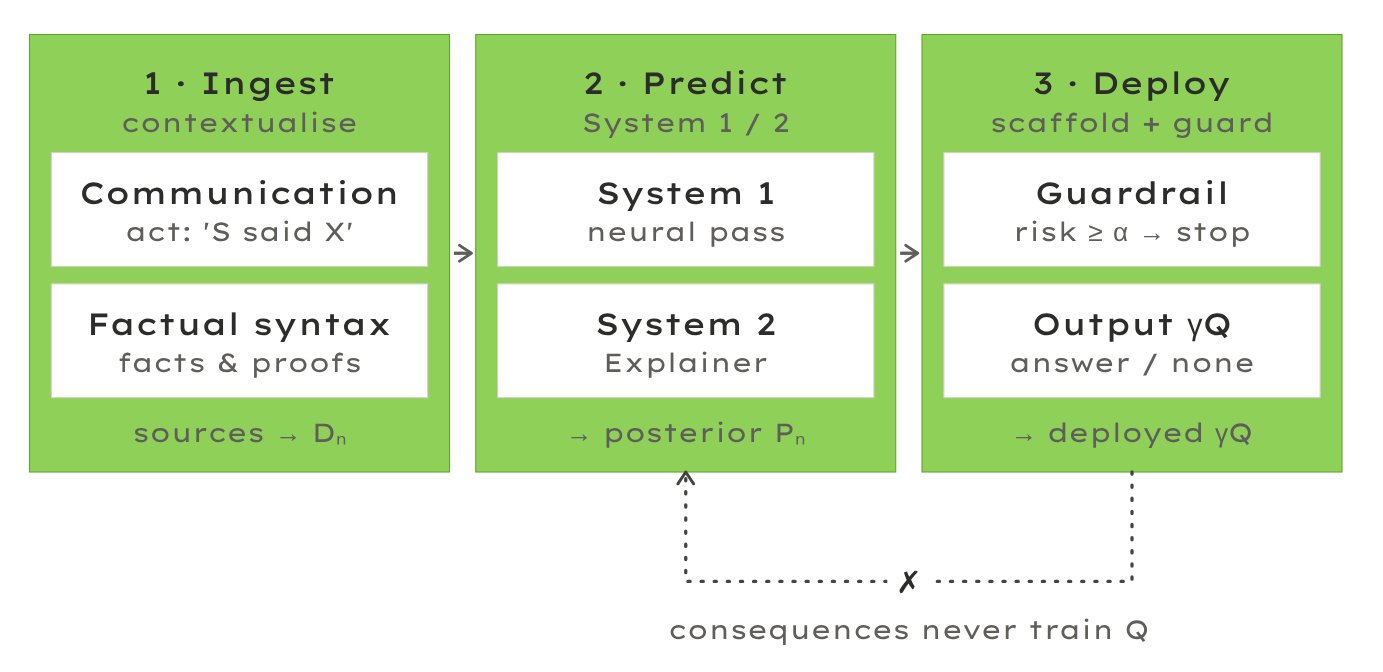
SAI is the contrary bet that we can well-predict agents without the predictor itself being an agent answering strategically (to model a manipulator doesn’t require being one?). Call a predictor honest if it just reports its Bayesian posterior: calibrated with no interest in the downstream.
As you’d hope from YB, it attempts to be bitter-pilled, to not fight the tide. It’s ultimately a training setup for a pair of neural nets: 1) a predictor Q approximating the posterior; 2) an explainer which proposes latent statements for Q to score. The guardrail is a second Q.
For this to work at all, you will need some interesting transforms of the training data: annotating whether it’s a communication act or a fact statement.
SAI is a very ambitious idea, and it’s even harder to make formal arguments about safety, even compared to other notoriously difficult real-world predicates (like security or average-case complexity). We anticipate objections throughout but you will have more.
Even after lots of constructive work, we have reservations about the core “consequence-invariance” (training that never selects predictors for what their outputs would cause) proof. But one paper does not need to solve the whole problem to be progress.
This paper responds to Gwern’s classic anti-tool post. It’s also an attempt to make Bayesian ML happen, a la Josh Tenenbaum. And in a funny way it’s also a long argument for Elon Musk’s (facially absurd) claim that, for safety, all you need is a really honest AI.
In general, we highly recommend designating some of your coauthors to be explicitly red-teamers, not responsible for fixing the claimed problems. Babble then prune.
Erdős Problem #1196 – a mathematical problem which has received a couple of person-years of human effort in the past – was recently solved by GPT-5.4 in an unusually insightful way. Terence Tao wondered how it did this.
We helped him out by simply providing 10 more runs from GPT. Together these make the problem look easy, in the limited sense that there are multiple sensible ways to solve it. The human effort had just gone awry at the first moment, by making a poor assumption (using probabilities instead of a discrete process):
Basically it seems that for this particular type of problem there are several natural ways to proceed that make the problem actually quite tractable; the literature had managed to focus on a somewhat suboptimal approach in which the opening move was to transfer the problem to a continuous setting, but the AI runs consistently stayed in the discrete world and managed to utilize various existing tools from discrete mathematics (mostly centering around methods relating to the LYM inequality) to reach a solution.
You can’t buy melatonin in the UK. In the US, it’s hard to avoid: it’s in gas station soft drinks. And: you can legally get bupropion online in the UK, while in the US it’s prescription only.
How general is this kind of thing?
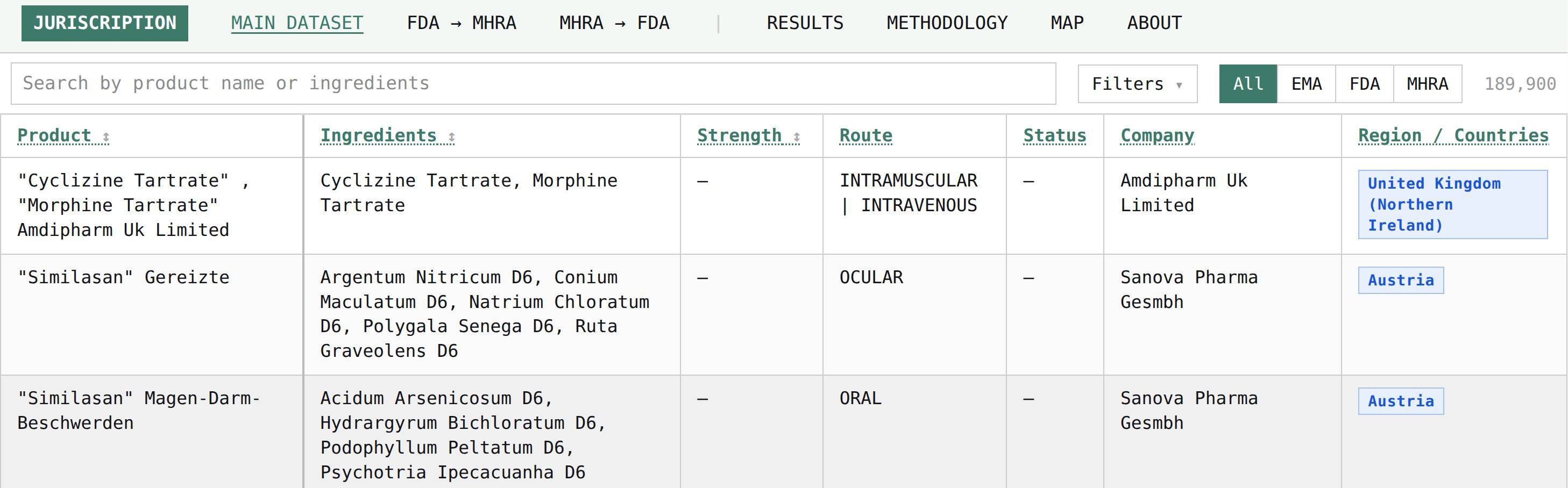
Our new beige site looks at every case where medical regulators disagree about whether to approve a medicine. We found 101 instances just between the US and UK.
We did this because we thought it would be easy with AI. As you can see from the methodology section, it was not.
Thanks to Emergent Ventures for funding and grudging thanks to Ben Southwood for bullying me into doing something concrete to improve the world for once.
Gavin did a Q&A with the Pathways to Progress reading group. Writeup making him sound coherent here.
PTP: There seems to be a strong narrative about AI coming from the people building these systems—many of whom have clear stakes in their success. At the same time, anecdotally, there also appears to be significant resistance among ordinary people. For example, at a high school I’m familiar with, it is socially uncool to use AI. In computer science classes, students who rely on AI to generate code are looked down upon. It feels like there is a real cultural tension. I was not around for earlier technological transitions, but it is hard to imagine high school students reacting this way to personal computers or smartphones. Is this backlash unique to AI? What explains it?
Gavin: First, skepticism is not limited to the general public. Many academics, even in 2026, remain unconvinced. In part, this may reflect early experiences: people tried the models two years ago, found them unimpressive, and have not revisited them since. Rapid progress means that impressions can quickly become outdated.
Among young people, there is also a cultural element. I teach teenagers, and perhaps 15 to 20 percent take pride in writing everything by hand. Whether or not they believe AI systems are capable, they see reliance on them as socially undesirable. That reaction is not surprising; new tools often clash with identity and norms, especially when the norms are associated with older generations or corporate culture.
More broadly, backlash to AI is not historically unusual. Throughout the history of technology, people have resisted adoption. Electric light had to compete with gas lighting. Trains had to overcome public fear. Major innovations routinely require persuasion, marketing, and social normalization. Resistance is a standard human response to large-scale change.
At the same time, AI appears to be one of the fastest-adopted technologies in history, likely even faster than smartphones. There is also evidence that usage is underreported. For example, workplace studies have shown that when people are asked whether their coworkers use AI—rather than whether they themselves do—reported usage rises significantly. One Microsoft study suggested that roughly half of workplace AI use was undisclosed at the time.
Regarding backlash, it is entirely possible for AI to be both the fastest-adopted technology in history and the subject of a highly organized counter-movement. There are numerous reasons people might oppose it: concerns about plagiarism, job displacement, aesthetic degradation of creative work, erosion of small online communities, misinformation, and increasing centralization of economic power. In extreme scenarios, we should worry about existential displacement: creating systems that no longer require humans at all.
New paper studying AI performance. (The Twitter thread is an accessible way in.)
In the past 3 years, LLM training corpuses expanded by a factor of 10000x. Does this increased chance of including test data confound apparent AI progress? What about including “semantic” duplicates, things which happen to be very similar to test data? And so how much of LLM performance is really down to “local” generalisation (pattern-matching to hard-to-detect semantically-equivalent training data)?
We experiment on OLMo 3, one of the only really good models with open training data. Since we have its entire training corpus, we can exhaustively check for real “natural” duplicates and finetune it to estimate their impact. We embed the entire training corpus.
We were surprised by how ineffective the standard n-gram decontamination is at catching exact duplicates - 70% of harder tasks had a match.
Every single MBPP test example and 78% of CodeForces have semantic duplicates.
So: n-gram decontamination is not enough even for the easy (exact) stuff, semantic duplicates are at least a moderately big deal, and this probably transfers to frontier models to some degree.
The first entry in a research programme with the grand aim of decomposing benchmark gains / apparent AI progress into 4 estimates:
benchmaxxing (memorising the test / paraphrasing / finetuning for a narrow task)
usemaxxing (RLing narrow capabilities in)
local generalisation (highly sophisticated pattern-matching but all bound by training data)
Deep OOD generalisation (e.g. algorithms that solve a whole problem class)
Obviously this will take a lot more work to nail down, and three times that much in closed models.
A couple of years ago, Gavin became frustrated with science journalism. No one was pulling together results across fields; the articles usually didn’t link to the original source; they didn’t use probabilities (or even report the sample size); they were usually credulous about preliminary findings (“…which species was it tested on?”); and they essentially never gave any sense of the magnitude or the baselines (“how much better is this treatment than the previous best?”). Speculative results were covered with the same credence as solid proofs. And highly technical fields like mathematics were rarely covered at all, regardless of their practical or intellectual importance. So he had a go at doing it himself.
This year, with Renaissance Philanthropy, we did something more systematic. So, how did the world change this year? What happened in each science? Which results are speculative and which are solid? Which are the biggest, if true?
Our collection of 201 results is here. You can filter them by field, by our best guess of the probability that they generalise, and by their impact if they do. We also include bad news (in red).
Data fields
Category. e.g. AI | Medicine | Protein design
Evidence type: A rough classification into Speculation / Demo / RCT, etc / Real-world evidence / Established fact
P(generalises). How likely we think it is to replicate or generalise, on priors. Preprint mathematics from a serious researcher is often around 90%. Preclinical in-vitro drug candidates are, notoriously, below 8%.
big | true. Every entry in the list is significant – scientifically, socially, or in delightfulness. But we wanted to weight them by impact. The “big if true” field is our guess at how much the entry would change the world if it generalised. We use Nate Silver’s “Technology Richter Scale”.
Good/Bad. whether we expect the net first-order effect of this to be positive for the world, or not.
Our judgments of P(generalises), big | true, and Good/Bad are avowedly subjective. If we got something wrong please tell us at gavin@arbresearch.com.
By design, the selection of results is biased towards being comprehensible to laymen, being practically useful now or soon, and against even the good kind of speculation. Interestingness is correlated with importance - but clearly there will have been many important but superficially uninteresting things that didn’t enter our search.
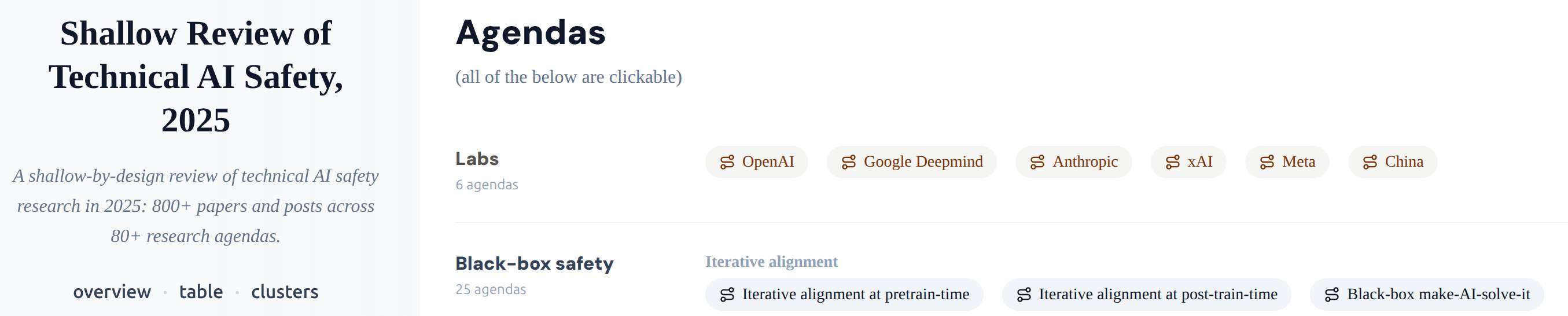
Every year we review what’s going on in technical AI safety. Here’s the third such ‘shallow’ review: 800 links in our taxonomy of 80 research agendas.
It’s shallow in the sense that 1) we are not specialists in almost any of it and that 2) we only spent two hours on each entry. Still, among other things, we processed every arXiv paper on alignment, all Alignment Forum posts, as well as a year’s worth of Twitter.
It is substantially a list of lists structuring around 800 links. The point is to produce stylised facts, forests out of trees; to help you look up what’s happening, or that thing you vaguely remember reading about; to help new researchers orient, know some of their options and the standing critiques; and to help you find who to talk to for actual information. We also track things which didn’t pan out.
Here, “AI safety” means technical work intended to prevent future cognitive systems from having large unintended negative effects on the world. So it’s capability restraint, instruction-following, value alignment, control, and risk awareness work.
Unpublished interviews with Jared Kaplan and Ajeya Cotra. Also Gavin wrote a bunch of essays, picked out the best hundred passages from the podcast, edited em into prose, fact-checked them, added definitions and citations, added some extra snark, designed a dozen visualisations. Very pleased about getting Gwern and Nostalgebraist into mainstream print. Juan wrote most of the semantic search and matplotlib code.
Also here’s an intense WebGL “living cover”, and here are reviews.
Gavin gave the keynote at the Human-Aligned AI Summer School 2025. The topic was “what’s going on in AI and AI safety”. The pace is a bit bracing. Recording here, slides here.
It’s basically a mid-year update on our big shallow review, ahead of the next edition in December.
We helped ACS write up their results on AIs preferring their own content to that of humans, and 18 months later it’s finally out in PNAS.
In an experimental design inspired by employment discrimination studies, we tested LLMs, including GPT-3.5 and GPT4, in binary-choice scenarios. These involved LLM-based agents selecting between products and academic papers described either by humans or LLMs under identical conditions. Our results show a consistent tendency for LLMs to prefer LLM-generated content.
(Figure 1 shows humans also preferring the LLM stuff in a couple of cases, but if you include estimate uncertainty it’s pretty near parity.)
This year we pivoted away from piecework and towards building ML tools. This is enabled by a client in the entertainment industry(!) and two generous grants from the Cosmos Institute and now SCSP.
Broadly, we’ll be adapting LLMs to the task of scenario analysis. This involves:
Automated scenario planning to envision risk.
Aiding users in policy and strategy analysis.
More importantly, create a method for rapidly exploring policy considerations. (Since speed demands may increase with accelerating AI progress.)
We will review the practice of strategy planning by shadowing high-level sessions; review the use of LLMs for geopolitical forecasting and related domains; scaffold LLMs for coherent policy and strategic analysis; test the tool on the questions of interest, yielding predictions on short-term questions; apply the tool to strategic questions about the impacts of AI on policy and strategy.
The project sounds grandiose (but isn’t): build a philosophical embedding space: use very high (e.g. 12,000-) dimensional vectors to replicate and extend philosophical space. By embedding a user’s own corpus, we will help people find their closest and farthest fellows, their hidden or received influences, their next interlocutor. Who is most dissimilar to you? Who might you be best served to read next, in surprisal?
I’m pretty disappointed in the shallowness of most LLM workflows and products and in the lack of public reaction to what has already changed. (There is now for the first time a nonhuman user of human language. What intelligence it has arises from extremely myopic and simple operations. This is a provocation and an important philosophical fact - consider just the effect on old “poverty of the stimulus” arguments.)
The hope is that tools like this let you interact with philosophy and literature - who influenced you, who directly, who independently converged on what you converged on. The cute “Which philosopher are you?” quiz associations of the user experience are hopefully just a lure to real engagement.
This year we completed 49 projects with 4.3 FTE. Mostly private work: only 8 are published and only another 5 outputs are likely to make it out.
Our private projects were on topics like semiconductors, fusion, brain emulation, AI incident reporting, org strategy, new ML benchmarks, civilisational resilience, the social benefit of a crop-processing factory, the theory of ML evals…
Gavin wrote a book with Dwarkesh Patel. Out around June.
Vox profiled our colleagues at Samotsvety Forecasting, including Misha.
A big paper on how to lie in machine learning (that is, on forty ways that evals are hard to make scientific).
We helped the Alignment of Complex Systems Group write up a result on AIs preferring their own content. Forthcoming in PNAS.
We finally published our big 90-page survey of AI’s likely effects from ten perspectives. ML, scientific applications, social applications, access, safety and alignment, economics, AI ethics, governance, and classical philosophy of life.
We got an Emergent Ventures grant to enumerate all cases where a medicine is approved in one jurisdiction and banned in another - and maybe arbitrage regulatory equivalence to get them automatically approved (where desirable!).
We submitted twoposts to ICLR’s new blogpost track.
Sam evaluated the AI Safety Camp (one of the earliest outreach programmes), at their behest.
We ran three summer camps for FABRIC: ASPR, Healthcamp and ESPR. Here's a flavour. Average student satisfaction 9.2 / 10 (but they are easily pleased).
Metaculus is hosting some of our AI forecasting questions and also David’s Minitaculus.
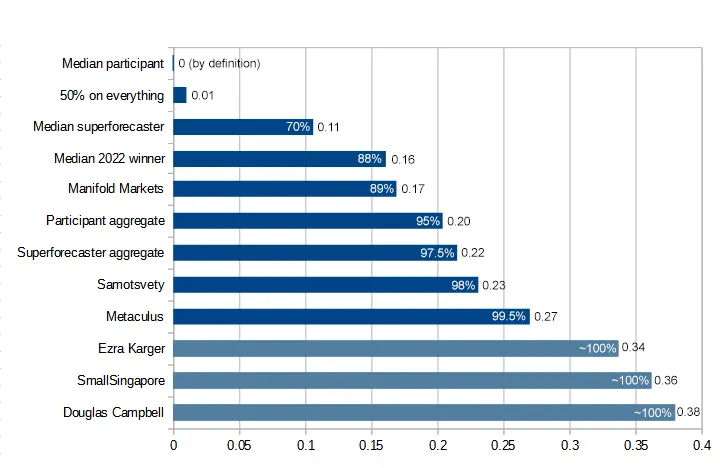
Gavin finally has a public track record; he was 89th percentile in the 2023 ACX Forecasting Contest (where the median single superforecaster was 70th).
We spent a month in California together, two months in London together, and two months in Taipei together.
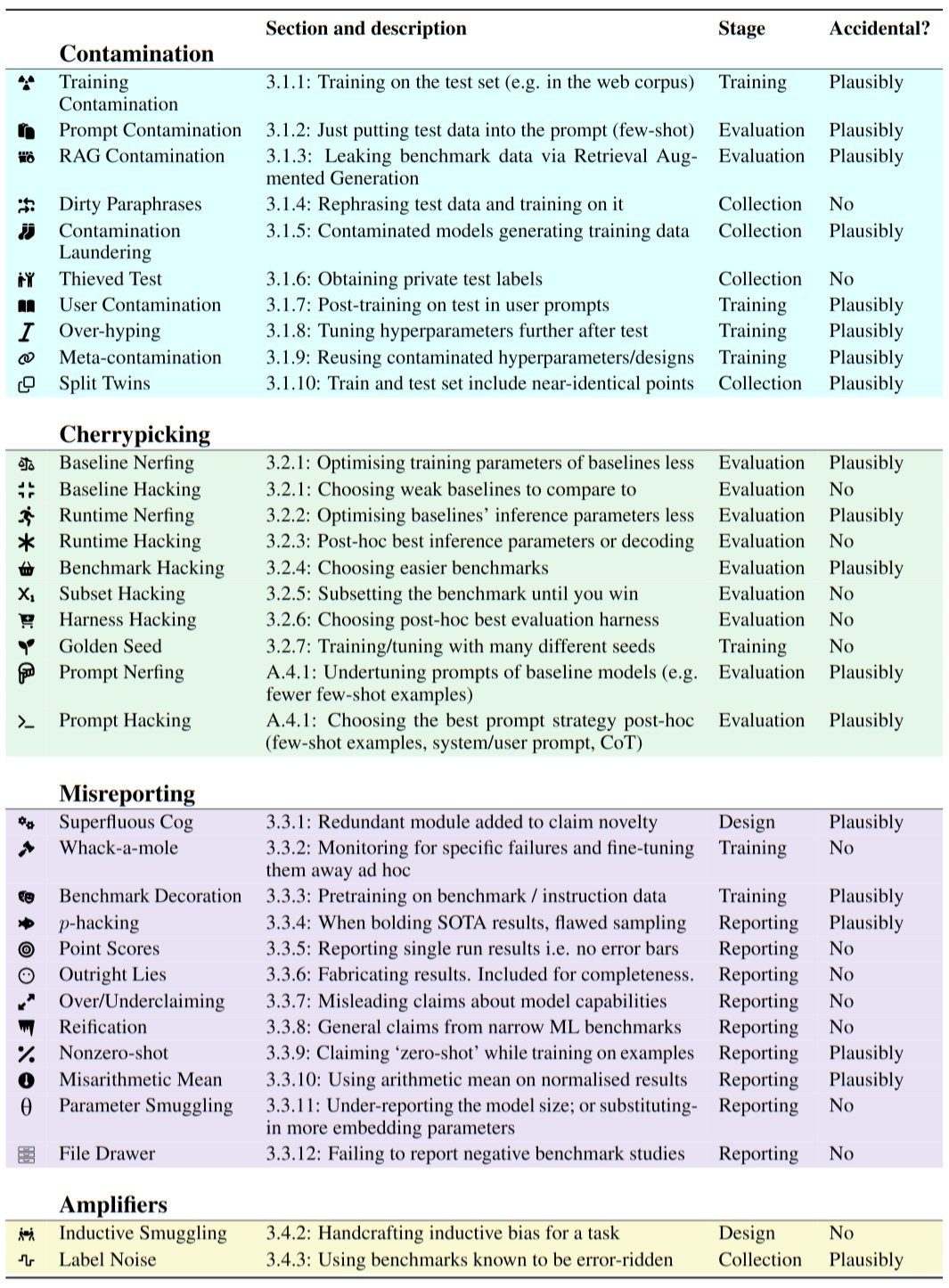
New paper - listing 43 ways ML evaluations can be misleading or actively deceptive. Following the good critics of bad psychological science we call these “questionable research practices” (QRPs).
Most of these upwardly bias benchmark scores, making LLMs look stronger than they are. Find it on arXiv or Twitter.
Samotsvetydid well in the 2023 ACX Forecasting Contest: 98th percentile, slightly beating the superforecaster aggregate. Notably, though, this was the result of one of them soloing it for 4 hours and then getting some feedback from the crew.
Metaculus has grown formidable, with their proprietary aggregate performing at the 99.5th percentile.
Gavin also finally has a public track record; he was 89th percentile (where the median single superforecaster was 70th and the Manifold aggregate of 150 nerds was also 89th).
Dylan Matthews put out a profile of Samotsvety Forecasting, including our very own Misha!
The name Samotsvety, co-founder Misha Yagudin says, is a multifaceted pun. “It’s Russian for semi-precious stones, or more directly ‘self-lighting/coloring’ stones,” he writes in an email. “It’s a few puns on what forecasting might be: finding nuggets of good info; even if we are not diamonds, together in aggregate we are great; self-lighting is kinda about shedding light on the future.”
It began because he and Nuño Sempere needed a name for a Slack they started around 2020 on which they and friends could shoot the shit about forecasting. The two met at a summer fellowship at Oxford’s Future of Humanity Institute, a hotbed of the rationalist subculture where forecasting is a favored activity. Before long, they were competing together in contests like Infer and on platforms like Good Judgment Open.
“If the point of forecasting tournaments is to figure out who you can trust,” the writer Scott Alexander once quipped. “the science has spoken, and the answer is ‘these guys.’”
They count among their fans Jason Matheny, now CEO of the RAND Corporation, a think tank that’s long worked on developing better predictive methods. Before he was at RAND, Matheny funded foundational work on forecasting as an official at the Intelligence Advanced Research Projects Activity (IARPA), a government organization that invests in technologies that might help the US intelligence community. “I’ve admired their work,” Matheny said of Samotsvety. “Not only their impressive accuracy, but also their commitment to scoring their own accuracy” — meaning they grade themselves so they can know when they fail and need to do better. That, he said, “is really rare institutionally.”
Note that Arb’s report, linked here, doesn’t support the claim Matthews makes ("The aggregated opinions of non-experts doing forecasting have proven to be a better guide to the future than the aggregated opinions of experts"). Instead we find that generalist supers are likely about as good as domain experts.
(with the crucial caveat that this is the status quo, where few experts care about calibration or have experience self-eliciting, and where the monetary rewards to be a super generalist are paltry in comparison to finance, so we’re not sampling the top there either).
We finally published our big 90-page intro to AI. Its likely effects, from ten perspectives, ten camps. The whole gamut: ML, scientific applications, social applications, access, safety and alignment, economics, AI ethics, governance, and classical philosophy of life. Intended audience: technical people without any ML experience.
We inherited the framing (“Ten Hard Problems”) from Eric Schmidt and James Manyika. They conditionalise on success: “if it’s 2050 and everything went well, what did we have to solve for that to happen?”
The problems that have to be handled:
HP #1: what general abilities do we need, for good outcomes?
HP #2: how do we make the things reliable and secure throughout their increasing power and pervasiveness?
HP #3: If they have goals of their own, how do we make sure they are compatible with ours?
HP #4: what great object-level technical problems will it help solve?
HP #5: how will we manage the macroeconomic shock?
HP #6: Who gets to build it? Who gets to use it? Who gets to benefit?
HP #7: what social and environmental damage needs to be prevented and mitigated?
HP #8: how do we coordinate various powerful actors’ use of AI?
HP #9: how does social infrastructure have to adapt? Who, if anyone, will govern it?
HP #10: what changes will the human condition undergo, after human exceptionalism and after historical materialism?
Sam evaluated the AI Safety Camp (one of the earliest such outreach programmes), at their behest.
We conducted a user survey, did email followups, calculated a few natural baselines, and produced a simple cost-benefit model.
Some headlines:
30% of survey respondents (n=24) believe that AISC greatly helped their career.
Our best guess is that it cost $12-30k per new researcher, vs an LTFF baseline of $53k.
8% of attendees at the 2020-2021 virtual camps plausibly changed their career trajectory towards AIS.
66% at these camps have output related to AI, and of these, 49% have some publication in AI (including arxiv).
Sam: “My expectation was that virtually all participants would be on a path to AIS without AISC and that evidence of a true trajectory change would be hard to find. However, there are several clear examples of individuals who changed their career trajectory towards AIS after camp and on surveys several respondents claim that this was directly because of AISC.”
As always, there are crucial problems with counterfactuals, selection bias, & heterogeneity (nonstationarity between camps and variance between the attendees) and the resulting numbers aren’t literal. We make a few conservative assumptions to try and dampen these effects. But I highly recommend the comment section.
We wrote two scientificpapers and a lit review on the topic of psychometrics and talent scouting. Less than 3 weeks to preprints. For Atlas.
Report on language models for biological tasks, and a forecast for when we will see AI generation of custom proteins.
We helped an alignment team test and write up an exciting result: efficient high-level control of language models at runtime. In review at ICML. For FAR.
See also a supplement piece we commissioned Nuño Sempere to write on general hurdles around forecasting AI, based on our experience writing these questions.
The series of reports and the question list represent 50 person-weeks of effort, including many dead ends.
[EDIT March 2024]: Some important questions from these are now a Metaculus series.
You can’t optimise an allocation of resources if you don’t know what the current one is. Existing maps of alignment research are mostly too old to guide you and the field has nearly no ratchet, no common knowledge of what everyone is doing and why, what is abandoned and why, what is renamed, what relates to what, what is going on.
We helped an alignment team test and write up an exciting result - maybe a step towards runtime steering of language model behaviour.
We investigate activation engineering: modifying the activations of a language model at inference time to predictably alter its behavior. It works by adding a bias to the forward pass, a ‘steering vector’ implicitly specified through normal prompts. Activation Addition computes these vectors by taking the activation differences of pairs of prompts.
We get control over high-level properties of the output without damaging the model’s performance. ActAdd takes far less compute and implementation effort compared to finetuning or RLHF, allows nontechnical users to provide natural language specifications, and it scales really naturally with model size.
This is the first(?) alignment method which doesn’t need training data or gradient descent.
We designed the experiments and wrote most of the resulting top conference submission including the figures and formalisations.
We want to know how regulations and less-formal norms (aka “soft law”) have helped to make the world safer in the past. This ties into Karnofsky’s project seeking precedents and models for coming AI regulation.
Rose interviewed several experts in biosecurity and soft law and drew some relatively confident conclusions.
Many standards are voluntary rather than legally mandated (e.g. BMBL)
International standards weren’t always later or less influential than national ones
Voluntary standards may be easier to internationalise than regulation
To increase compliance internationally, people funded biosafety associations and offered free training
Bio standards are often list-based. (not comprehensive, do not reflect new threats, prevent innovation, and fail to address context)
There’s been a partial move away from prescriptive, list-based standards towards holistic, risk-based standards (e.g. ISO 35001)
Bio standards tend to lack reporting standards, so it’s very hard to tell how effective they are
In the US, no single body or legislation is responsible for making or monitoring bio standards
There are conflicts of interest: the same body responsible for funding research and assessing its safety
We reviewed the literature on using language models for modelling protein sequences. We give some high-level conclusions about the likely timeframe and proliferation risk.
The Institute for Progress just published our elaboration on our previous work on experts vs amateur forecasters.
We cut a bunch of introductory material which you can see here.
Most of the goodness is hidden in the links, like the literature review which compares each pair of forecasting methods. Thanks to Alejandro for organising this.
See also this list of forecasting platforms open to you.
Magazine style omits acknowledgments, so thanks to Alejandro Ortega, Sam Enright, Sam Harsimony, Sam Glover, the Irish Sam Bowman, David Mathers, Patrick Atwater, Max Langenkamp, Christian Robshaw, Ozzie Gooen, Kristi Uustalu, Michael Story, Nick Whittaker, Philip Stephens, Jeremy Neufeld, Adam Russell, Alec Stapp, Santi Ruiz and the ubiquitous Nuño Sempere for often large amounts of input. Thanks to Steve for amazing editing.
We answered the question "What makes new intellectual fields and movements succeed?", forthcoming for [client].
Paper on all the problems AI could cause, written for Schmidt Futures.
Our sister org Samotsvety answered some important forecasting questions: 1) the risk of a nuclear strike after the Ukraine invasion; 2) the risk of a catastrophe caused by AI this century.
Other projects
We collated every public forecast about AI and noted weaknesses and gaps, for [client].
Misha, Eli, and Aaron cofounded Sage, a forecasting service / code shop. Their first public product is the epistemic training site Quantified Intuitions.
As part of Samotsvety Forecasting, Misha estimated the risk arising from near-future artificial intelligence systems. They also took a baseline from a potentially less biased baseline group. The definition used is here.
Holden Karnofsky commissioned us to evaluate the track record of “the Big Three” of science fiction: Asimov, Heinlein, and Clarke.
We formed a team, wrote a pipeline, and processed 475 works (one-third of their entire collected corpus), manually tagging and annotating everything. Asimov is the standout, with roughly 50% accuracy.
What’s the point?: To see if the speculation that effective altruism has switched to has any precedent; if it ever works.
Holden’s writeup here, our report here. Bug bounty described in the latter.
Gavin is a judge on a contest awarding cash prizes to new criticisms of effective altruism. We want points from outside the EA bubble and there’s an option to pay you an advance if you need one.
We’re leading a study of AI talent for the Mercatus Center. This goes with the new Emergent Ventures AI tranche. We’ll boost underappreciated researchers and builders; give us leads!
We helped Jan Kulveit, research scholar at FHI and cofounder of the Epidemic Forecasting initiative, to review the EA response to Covid. He has many interesting general insights into the nature of long-termism and world resilience.
Samotsvety estimated nuclear risk arising from the war in Ukraine. Misha was commissioned by CEA to monitor the situation and provide updates. The piece received vigorous feedback, including a dissenting opinion by J. Peter Scoblic. Funded retroactively through the FTX Future Fund regranting program.
Misha and his Samotsvety colleagues were commissioned to look at the track record of internal prediction markets.
“More sure that prediction markets fail to gain adoption than why this is.”















{kind=link}